
| Email |
Google Scholar |
|
I am a Ph.D. student in Artificial Intelligence at the AI Thrust, Information Hub, The Hong Kong University of Science and Technology (Guangzhou), advised by Prof. Junwei Liang. I received my Bachelor's degree from the Honors College of Beihang University (BUAA), supervised by Prof. Baochang Zhang and Prof. David Doermann. I also spent time at OpenGVLab, Shanghai AI Lab, collaborated with Dr. Peng Gao and Prof. Hongsheng Li. Research Interest: The intersection of large-scale pre-training, generalizable manipulation and whole-body control, . Research Question: How can we build robots that perceive, reason, and act in the open world with human-like generalization? Email: telima9868 [AT] gmail.com / tma184 [AT] connect.hkust-gz.edu.cn |
|
{kind=link}
|
* indicates equal contribution. |
|
webpage |
pdf |
bibtex
@misc{wang2026perceptivebehaviorfoundationmodel,
title={Perceptive Behavior Foundation Model: Adapting Human Motion Priors to Robot-Centric Terrain},
author={Zifan Wang and Yizhao Li and Teli Ma and Qiang Zhang and Yudong Fan and Hao Xu and Shuo Yang and Junwei Liang},
year={2026},
eprint={2606.08059},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.08059},
}
|
|
|
webpage |
pdf |
bibtex
@misc{zheng2026motionwamfoundationworldaction,
title={MotionWAM: Towards Foundation World Action Models for Real-Time Humanoid Loco-Manipulation},
author={Jia Zheng and Teli Ma and Yudong Fan and Zifan Wang and Shuo Yang and Junwei Liang},
year={2026},
eprint={2606.09215},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.09215},
}
|
|
|
webpage |
pdf |
bibtex |
code
@article{ma2026dit4dit,
title={DiT4DiT: Jointly Modeling Video Dynamics and Actions for Generalizable Robot Control},
author={Ma, Teli and Zheng, Jia and Wang, Zifan and Jiang, Chunli and Cui, Andy and Liang, Junwei and Yang, Shuo},
journal={arXiv preprint arXiv:2603.10448},
year={2026}
}
|
|

|
webpage |
pdf |
bibtex |
arXiv |
code
@misc{wang2025omniperception,
title={Omni-Perception: Omnidirectional Collision Avoidance for Legged Locomotion in Dynamic Environments},
author={Zifan Wang and Teli Ma and Yufei Jia and Xun Yang and Jiaming Zhou and Wenlong Ouyang and Qiang Zhang and Junwei Liang},
year={2025},
eprint={2505.19214},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2505.19214},
}
|

|
webpage |
pdf |
bibtex |
arXiv |
code
@article{ma2025glover++,
title={GLOVER++: Unleashing the Potential of Affordance Learning from Human Behaviors for Robotic Manipulation},
author={Ma, Teli and Zheng, Jia and Wang, Zifan and Gao, Ziyao and Zhou, Jiaming and Liang, Junwei},
journal={arXiv preprint arXiv:2505.11865},
year={2025} }
|

|
webpage |
pdf |
bibtex |
arXiv |
code
@article{ma2024glover,
title={Glover: Generalizable open-vocabulary affordance reasoning for task-oriented grasping},
author={Ma, Teli and Wang, Zifan and Zhou, Jiaming and Wang, Mengmeng and Liang, Junwei},
journal={arXiv preprint arXiv:2411.12286},
year={2024}
}
|
|
webpage |
pdf |
bibtex |
arXiv |
code
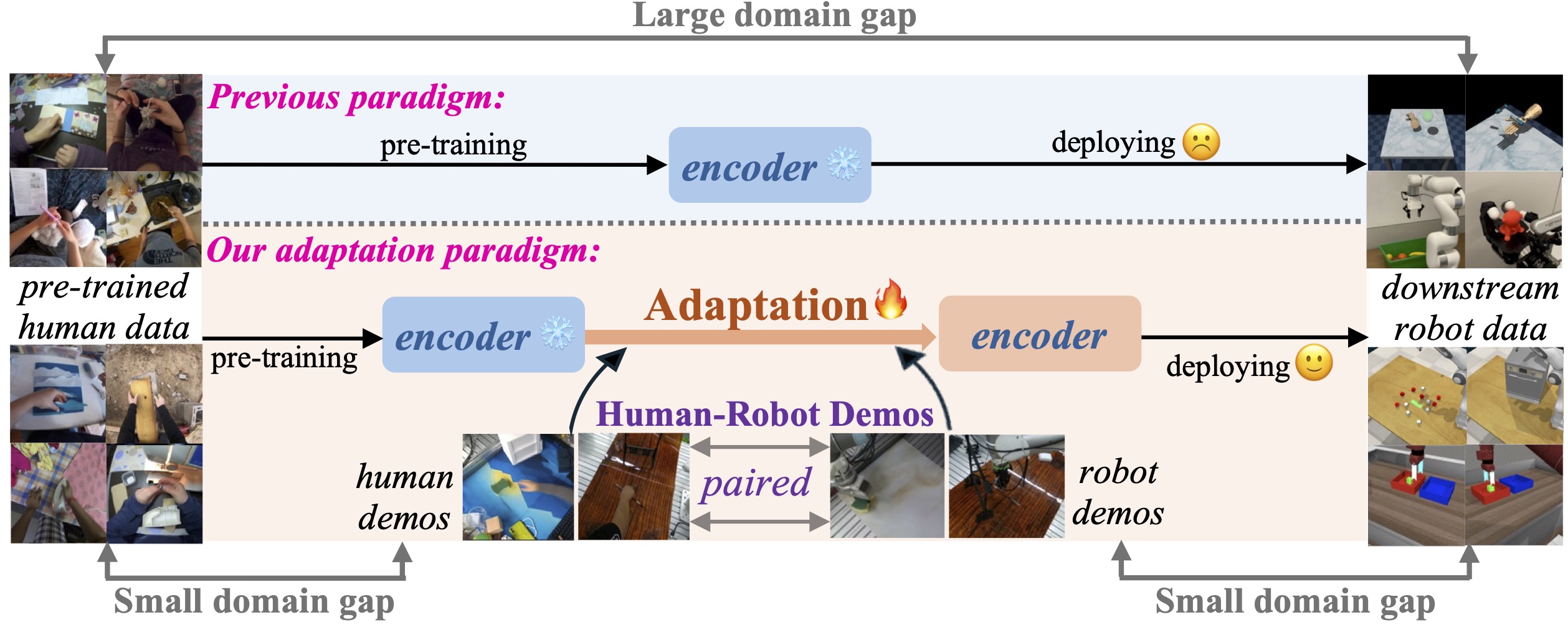
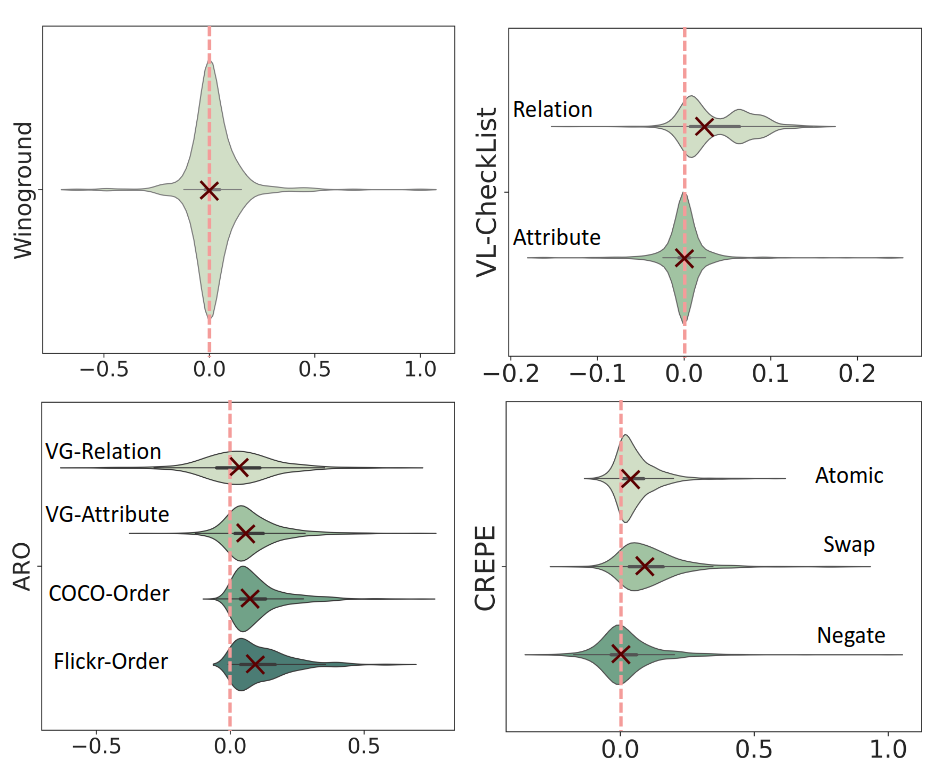
@article{zhou2024mitigating,
title={Mitigating the Human-Robot Domain Discrepancy in Visual Pre-training for Robotic Manipulation},
author={Zhou, Jiaming and Ma, Teli and Lin, Kun-Yu and Qiu, Ronghe and Wang, Zifan and Liang, Junwei},
journal={arXiv preprint arXiv:2406.14235},
year={2024}
}
|
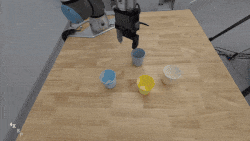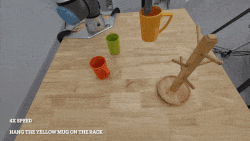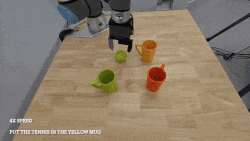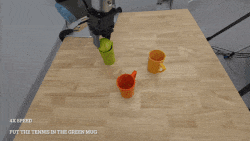
|
webpage |
pdf |
bibtex |
arXiv |
code
@article{ma2024contrastive,
title={Contrastive imitation learning for language-guided multi-task robotic manipulation},
author={Ma, Teli and Zhou, Jiaming and Wang, Zifan and Qiu, Ronghe and Liang, Junwei},
journal={arXiv preprint arXiv:2406.09738},
year={2024}
}
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
AAAI Conference on Artificial Intelligence (AAAI), 2025
International Conference on Learning Representations (ICLR), 2024, 2025, 2026 International Conference on Machine Learning (ICML), 2024, 2025, 2026 Conference on Computer Vision and Pattern Recognition (CVPR), 2022, 2023, 2024, 2025, 2026 European Conference on Computer Vision (ECCV), 2024, 2026 International Conference on Computer Vision (ICCV), 2023, 2025 Conference on Robot Learning (CoRL), 2025, 2026 Conference on Neural Information Processing Systems (NeurIPS), 2023, 2024, 2025 IEEE Robotics and Automation Letters (RA-L), 2025 |