An Examination of the Compositionality of Large Generative Vision-Language Models
ABSTRACT
With the success of Large Language Models (LLMs), many Generative Vision-Language Models (GVLMs) have been constructed via multimodal instruction tuning. However, the performance of GVLMs in multimodal compositional reasoning remains under-explored. In this paper, we examine both the evaluation metrics ( VisualGPTScore, etc.) and current benchmarks for evaluating the compositionality of GVLMs. We identify the syntactical bias in current benchmarks, which is exploited by the linguistic capability of GVLMs. The bias renders VisualGPTScore an insufficient metric for assessing GVLMs. To combat this, we first introduce a SyntaxBias Score, leveraging LLMs to quantify such bias for mitigation. A challenging new task is subsequently added to evaluate the robustness of GVLMs against inherent inclination toward syntactical correctness. Using the bias-mitigated datasets and the new task, we propose a novel benchmark, namely SyntActically DE-biased benchmark (SADE). Our study provides an unbiased benchmark for the compositionality of GVLMs, facilitating future research in this direction.


HIGHLIGHTS
* A prevalent syntactical bias is present in contemporary multimodal compositional reasoning benchmarks.These benchmarks are tailored for assessing EVLMs, and the approach used to create negative references may not be effective for the evaluation of GVLMs.

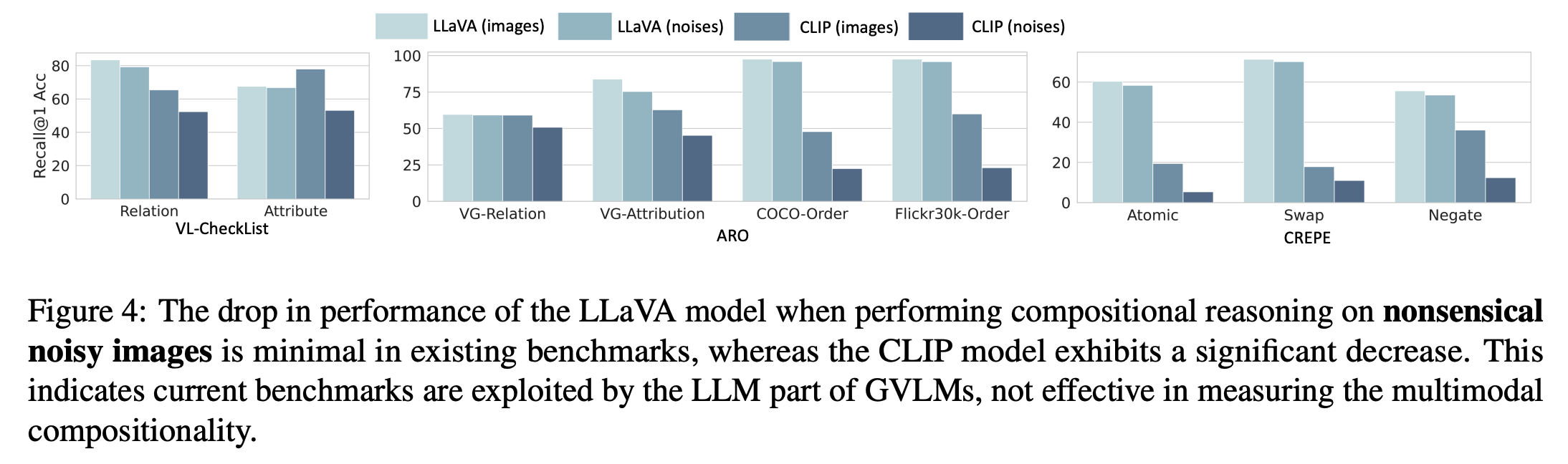
* We quantitatively analyze the syntactical bias (namely SyntaxBias Score) that broadly exists in current benchmarks by leveraging LLMs.
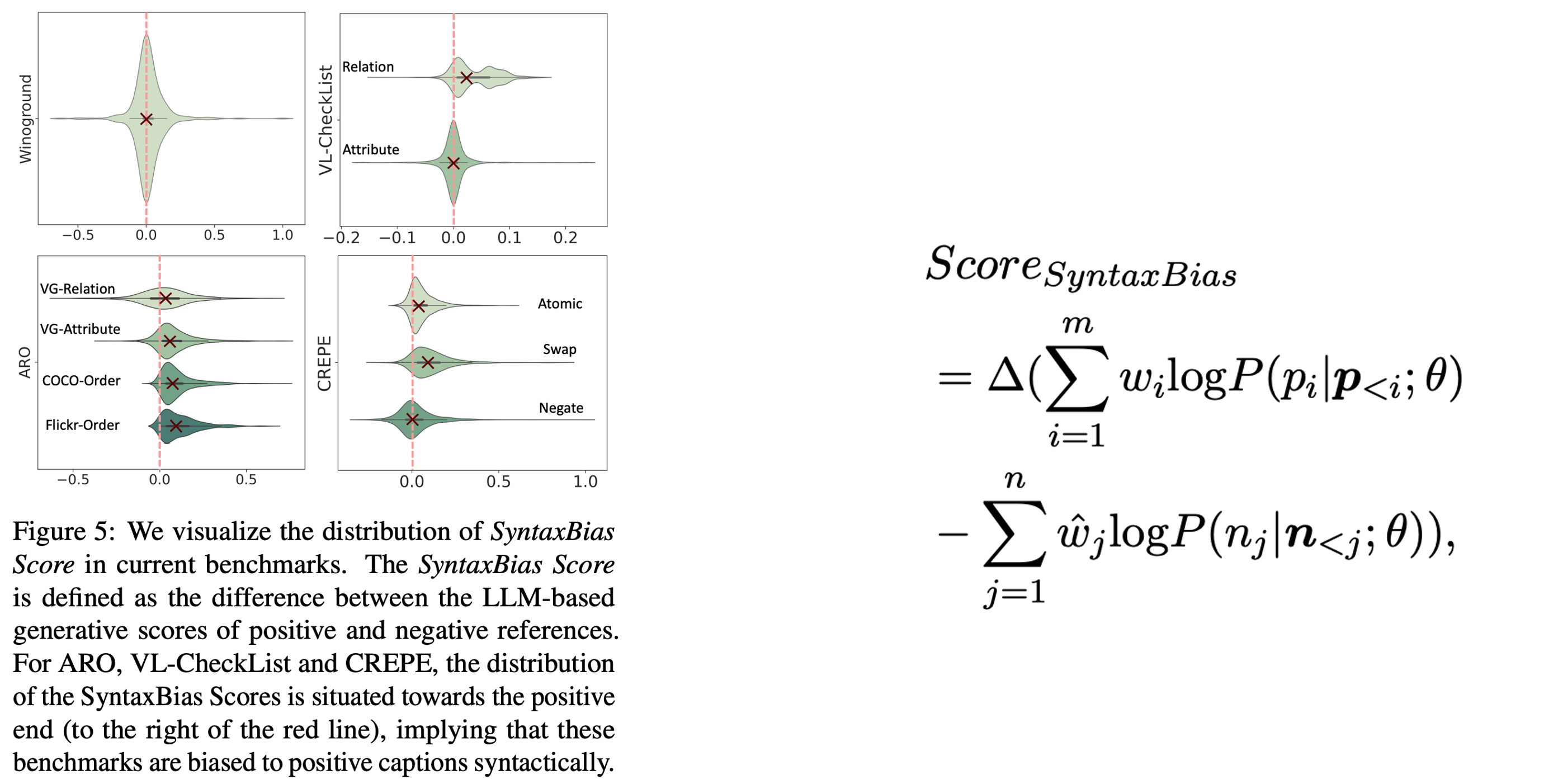
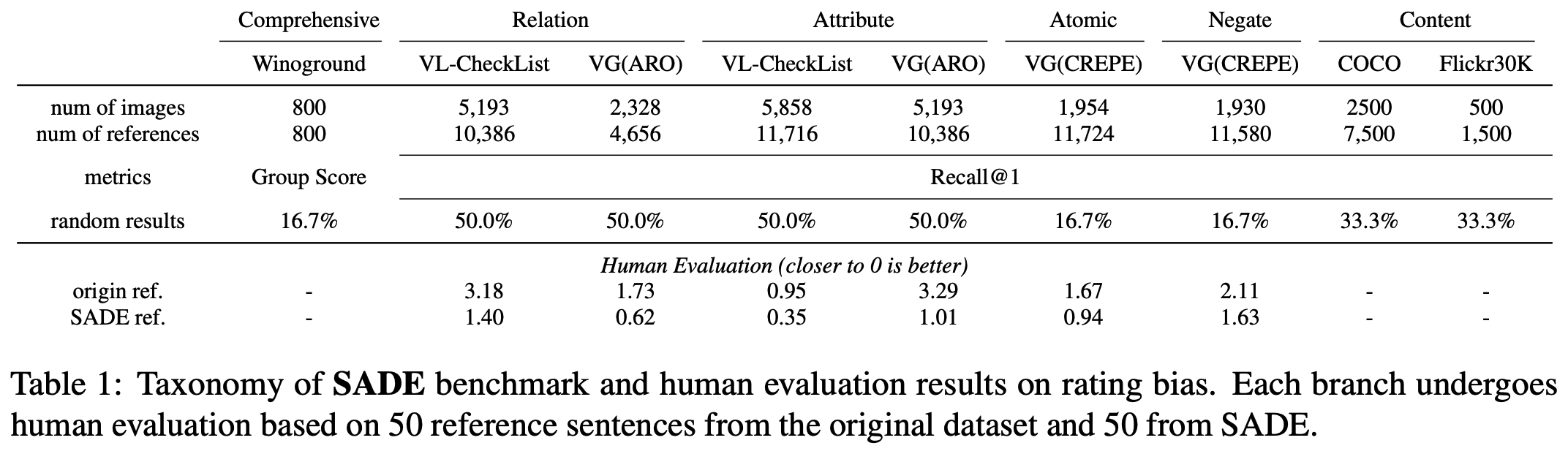
* With the SyntaxBias Score, we propose a SyntActically DE-biased benchmark (SADE) based on current benchmarks for a more robust multimodal compositionality evaluation. We adopt multiple strategies to mitigate the syntactical bias in existing benchmarks. We also add a new challenging assessment in SADE to evaluate the content understanding across visual and language modalities.

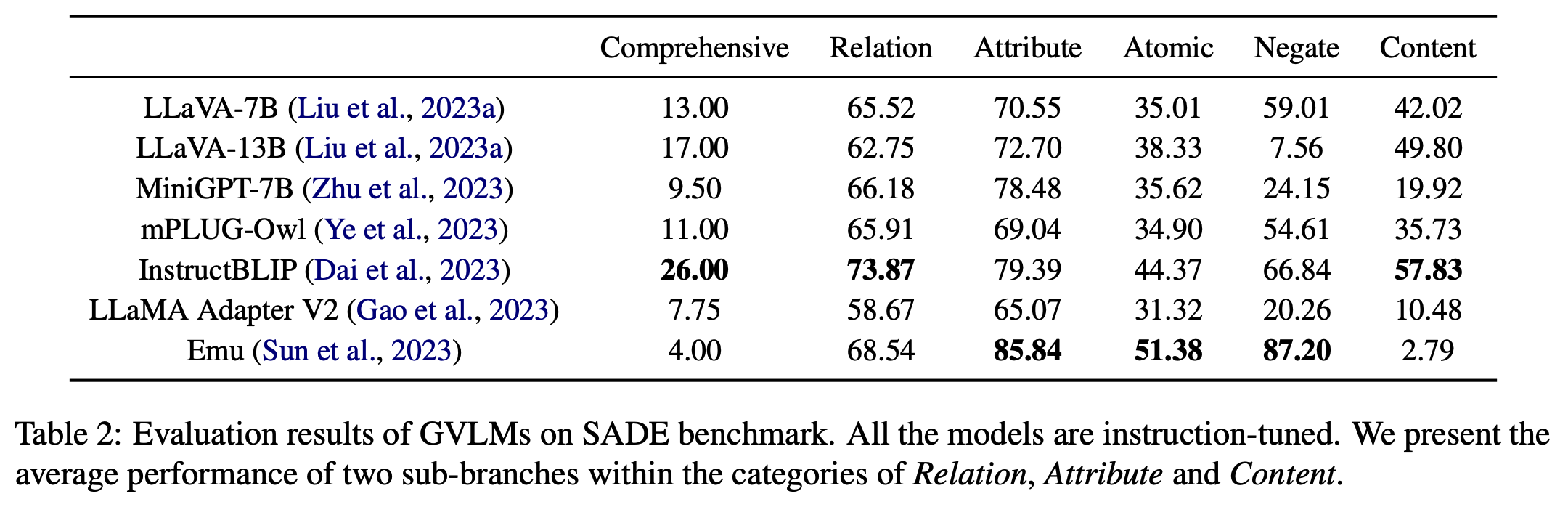
* The performance of several GVLMs is reported on SADE, as well as the robustness and faithfulness to human judgments.
CITATION
@article{ma2023examination,
title={An examination of the compositionality of large generative vision-language models},
author={Ma, Teli and Li, Rong and Liang, Junwei},
journal={arXiv preprint arXiv:2308.10509},
year={2023}}